Cari amici del Codice Pelavicino Edizione Digitale
come promesso eccovi alcune informazioni sulle modifiche fatte allo schema di codifica, opera di Chiara Di Pietro ed Alessio Miaschi
Gestione di integrazioni e aggiunte editoriali
In particolare di due tipologie di testo mancante che viene integrato dall’editore:
- integrazione ex ingenio di una o più parole (ma tendenzialmente di un testo breve o brevissimo) tralasciato dal copista per distrazione;
- integrazione di una o più parole (anche frammenti di testo più lunghi) omesse dal copista e ricavabili dallo studio di altre fonti.
La codifica <add place=”inline”> utilizzata fino ad oggi è stata modificata come segue:
- errori o omissioni del copista
<supplied reason=”omitted”> testo integrato perché omesso </supplied>
reso graficamente come segue <testo integrato perché omesso>
- parole illeggibili
<supplied reason=”illeggibile”> testo integrato perché illeggibile </supplied>
reso graficamente come segue [testo integrato perché illeggibile]
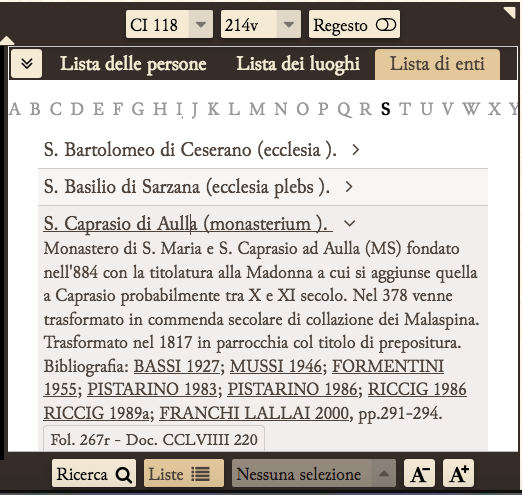
Aggiunta codifica e gestione delle liste di enti religiosi.
A livello di codifica la lista degli enti è stata marcata come segue:
<org xml:id=”Ceparana“>
<orgName type=”monasterium”>
S. Venanzio di Ceparana
</orgName>
<desc>
Il monastero di S. Venanzio di Ceparana, sito in […]
</desc>
</org>
Come si vede, è stato utilizzato il tag <orgName> e per ogni entità è stata specificata la tipologia per mezzo dell’attributo @type.
La singola occorrenza nel testo è stata invece codificata per mezzo del tag <orgName> e collegata all’entità per mezzo dell’attributo @ref.
<orgName ref=“#Ceparana”>
monasterium sancti Venantii
</orgName>
A livello di visualizzazione, gli enti religiosi sono stati gestiti come le altre named entities presenti (nomi di persona e nomi di luogo)
- presenza di popup esplicativo al click sul testo che identifica l’ente
- lista di enti religiosi, con possibilità di visualizzare le occorrenze per ciascuno
Aggiunta codifica e gestione dei documenti con struttura tabellare.
A livello di codifica, i documenti con struttura tabellare sono così codificati:
<table rows=”2” cols=”2”>
<head>Intestazione tabella:</head>
<row role=”data”>
<cell> Testo </cell>
<cell> Testo </cell>
</row>
<row role=”data”>
<cell> Testo </cell>
<cell> Testo </cell>
</row>
Come si può vedere, l’elemento <table> viene utilizzato per marcare l’inizio della tabella, mentre i suoi due attributi @rows e @cols specificano il numero totale delle righe e delle colonne. All’interno di ogni elemento <table> abbiamo: un <head> per l’intestazione della tabella e una serie di elementi <row>, tanti quante sono le righe indicate nell’attributo @rows. A sua volta, all’interno di ogni <row> sono predisposte una serie di <cell>, in numero uguale a quelle definite nell’attributo @cols.
Visualizzazione

Aggiunta codifica e gestione dei documenti su colonne:
A livello di codifica, per suddividere il testo in colonne si utilizza:
<cb n=”1” rend=”2col_layout” xml:id=”CCCXLVI_cb_001”/>
Dove l’attributo @n specifica il numero della colonna alla quale apparterrà il testo seguente, @rend definisce il numero totale di colonne che avrà il dato documento (2col_layout vuol dire che ne avrà due) e @xml:id è l’identificatore specifico della colonna per il dato file XML.
Visualizzazione
